
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- remix
- nodejs
- Apache Spark
- Greeter
- lambda
- 블록체인
- Ethereum
- OpenCV
- Spark
- pyspark
- word count
- Histogram
- apache-spark
- macbook
- python3
- RDD
- MAP
- geth
- web3
- jenv
- HelloWorld
- node
- stopwords
- solidity
- docker
- Python
- 이더리움
- bigdata
- web3@1.2.8
- BlockChain
- Today
- Total
이것저것 프로그래밍 정리(Macbook)
apache-spark의 RDD - pyspark 본문
RDD
spark 에서 RDD는 핵심이다.
RDD는 데이터가 비구조적인 경우에 사용하기 적합하다.
RDD는 Resilient Distributed Dataset의 약자이다. Resilient는 작업이 실패하지 않도록 falut tolerent 한것, 즉 어느 한 노드에서 작업이 실패하면 다른 노드에서 실행하는 것을 의미하고 Distributed는 클러스터로 구성된 여러 노드에 분산해서 처리하는 것을 의미하고 Dataset은 말 그대로 데이터 구조를 의미한다.
RDDsms Python 리스트, 파일, hdfs 등 다양한 자료에서 생성할 수 있고, 생성된 RDD는 수정할 수 없는 Read-Only 이다.
RDD에 관한 개념적 내용은 보다 더 자세히 공부한 이후에 올리도록 하고 일단 실질적으로 RDD를 생성하고 RDD를 이용해 보도록 하자.
1. RDD 생성
RDD는 sparkContext로부터 생성된다.
배열과 같은 자료구조 혹은 외부 파일을 읽어서 RDD를 생성한다.
1.1 Python list에서 RDD 생성, 확인
sparkContext.parallelize() 함수를 통해서 RDD를 생성 할 수 있다.
개발환경은 jupyter notebook에서 진행하는 중이니 만약 spark를 jupyter notebook에서 활용하는 법을 모르겠으면 밑의 링크를 참고하도록 하자.
https://parkaparka.tistory.com/2
apache-spark 시작하기(Macbook)
스파크 사용 이유는? 먼저 데이터가 엄청난 양으로 증가되며, 이를 처리하기 위해 분산 프레임워크인 Hadoop과 최근에 Spark가 많이 쓰이고 있다. Hadoop은 데이터를 수집하는 목적으로 많이 사용된다. spark는 수..
parkaparka.tistory.com
예제와 함께 RDD를 생성해도록 하자.

위 사진과 같은 방법으로 python의 list형식의 myList를 sparkContext.parallelize() 함수를 통해 RDD인 myRdd를 생성해 보았다.
이제 만들어진 RDD를 확인해 보도록 하자.

myRdd.first()를 통해 만들어진 RDD의 첫번째 값인 1을 확인 할 수 있다.
myRdd.take(3)를 통해 만들어진 RDD의 첫 3개의 값인 1,2,3 을 확인 할 수 있다.
myRdd.collect()을 통해 만들어진 RDD의 전체 값을 확인 할 수 있다.
1.2 파일에서 RDD 생성, 확인
이번에는 외부 파일에서 RDD를 생성하고 그 값을 확인 해보자.

data라는 폴더 안에 ds_spark_ex.txt라는 파일을 만들고 이 파일을 sparkContext.textFile() 함수를 통해 RDD를 생성하였다.
이제 생성된 RDD를 확인해 보도록 하자.
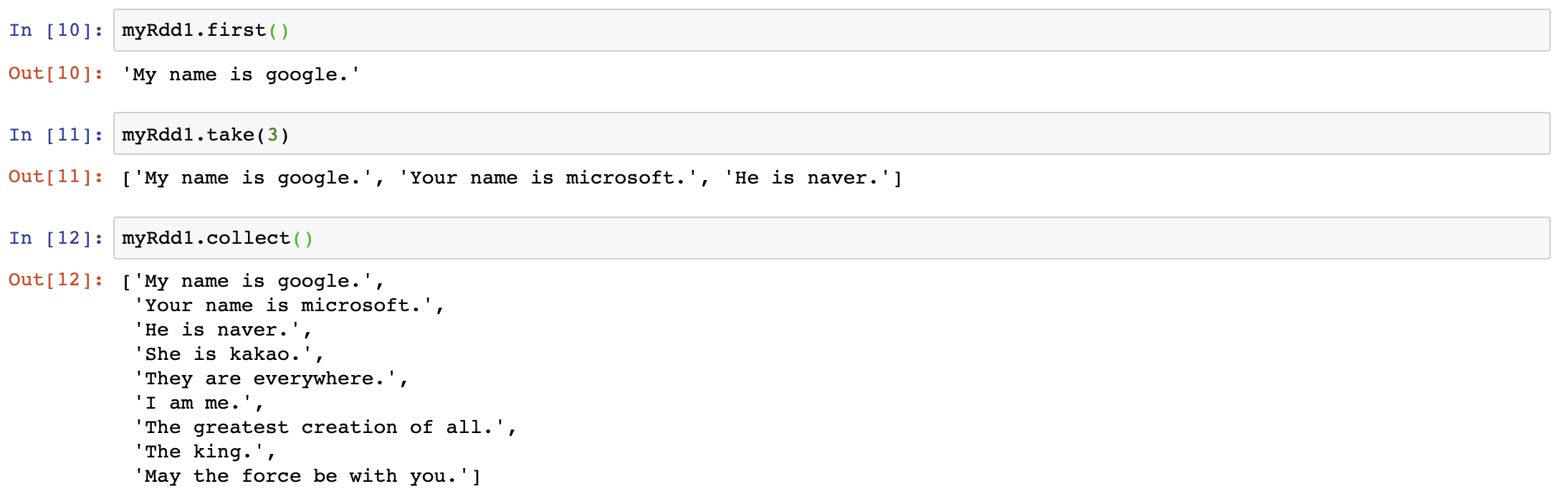
python list와 마찬가지로 .first(), .take(), .collect() 함수를 사용하여 RDD값을 확인해 볼 수 있다.
이번에는 외부파일 .txt 파일이 아닌 .csv 파일에서 RDD를 생성해 보자.

data라는 폴더 안에 ds_spark_csv.csv라는 csv파일을 만들고 이 파일을 sparkContext.textFile() 함수를 통해 RDD를 생성하였다.
이제 생성된 RDD를 확인해 보도록 하자.

RDD 생성하고 확인하는 방법을 배워 보았고 다음 글에서는 생성한 RDD를 map, lambda 등 다양한 함수를 통해 데이터를 가공해보도록 하자.
'apache-spark(big data)' 카테고리의 다른 글
| apache-spark 에서 word count하기(2) - pyspark (0) | 2020.04.28 |
|---|---|
| apache-spark 에서 word count하기(1) - pyspark (0) | 2020.04.27 |
| apache-spark에서 map,lambda 함수 활용하기(2) - pyspark (0) | 2020.04.24 |
| apache-spark에서 map,lambda 함수 활용하기(1) - pyspark (0) | 2020.04.22 |
| apache-spark 시작하기(Macbook), spark 설치, pyspark (0) | 2020.02.18 |



