
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- nodejs
- MAP
- macbook
- solidity
- bigdata
- apache-spark
- lambda
- pyspark
- geth
- Python
- Greeter
- BlockChain
- word count
- 이더리움
- web3@1.2.8
- Apache Spark
- OpenCV
- Histogram
- 블록체인
- Ethereum
- jenv
- remix
- node
- python3
- web3
- stopwords
- docker
- RDD
- Spark
- HelloWorld
- Today
- Total
이것저것 프로그래밍 정리(Macbook)
apache-spark 에서 word count하기(2) - pyspark 본문
https://parkaparka.tistory.com/16
apache-spark 에서 word count하기(1)
대문자, 소문자 변환 단어의 객수 count 하기, word count 하기를 앞서서 대문자로 되어있는 단어와 소문자로 되어있는 단어는 모두 같기 때문에 대소문자 변경하는 것을 먼저 알아보도록 하자. 먼저 예시 dataset..
parkaparka.tistory.com
저번 word count에 이어서 이번에는 필요 없는 불용어를 문장에서 제거하고 word count 하는 방법을 알아보도록 하자.
불용어를 먼저 설정해 보도록 하자.

훨씬 많은 불용어들이 있지만, 위와 같이 일부의 불용어만 설정해 보았다.

위 ds_bigdata_stopwords_ex.txt 예제에 나오는 문장을 예제로 word count를 해보도록 하자.
spark의 RDD를 통해서 하기 전에 python을 통해서 먼저 word count를 해 보도록 하자.
Python 사용
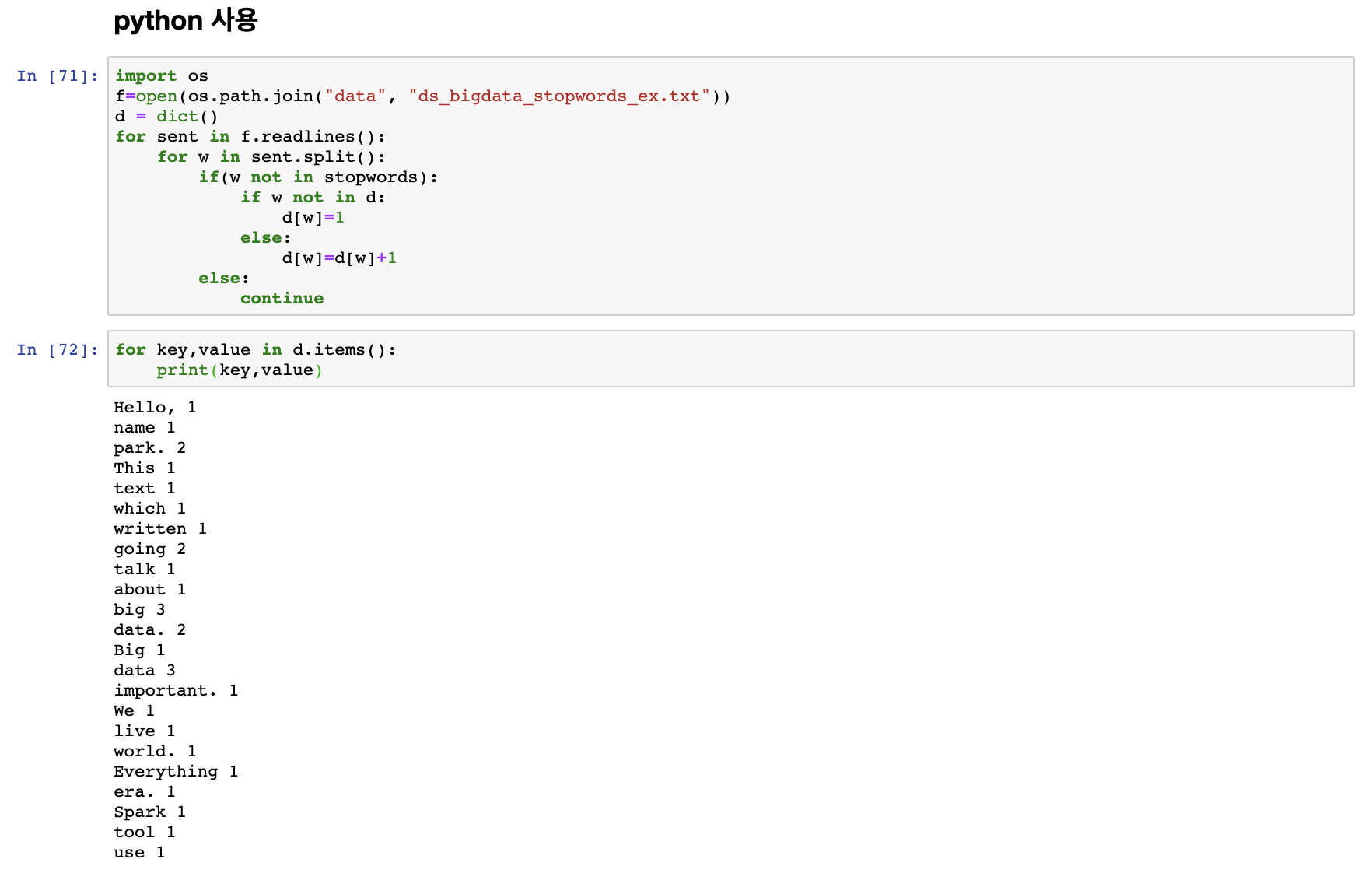
dictionary 를 생성한 이후 key, value 값을 이용해 dictionary에 해당단어가 stopwords에 해당하지 않으면 dictionary에 추가하는 방식으로 이루어 진다.
RDD 사용
spark를 통해 word count를 해주기 위해서 먼저 ds_bigdata_stopwords_ex.txt 를 RDD로 만들어주 주도록 하겠다.

RDD 생성 이후 collect() 를 통해 만들어진 것을 확인해 주도록 하자.
이후 이제 만들어진 RDD를 flatMap() 을 통해 하나에 리스트에 들어갈수 있게 해주자.

위와 동일하게 flatMap() 이후 collect()를 통해 결과물을 확인해 보도록 하자.
이번에는 생성된 myRdd_stop 안에서 stopwords에 해당하는 것들은 걸러 내주도록 하자.

이제 stopwords를 제외한 각 단어별로 RDD가 생성되었으니 pair RDD를 생성해서 각 단어의 갯수를 세어보도록 하자.

pair RDD 생성이후 key로 그룹지어서 각 단어가 몇번 나왔는지 key에 따라 정렬해준 결과물이다.
위 과정들은 word count 하기 위해서 여러줄을 한 줄로 나눈 것들이다.
위의 것들을 한줄로 결과를 확인해 보도록 하자.

이렇게 한줄로 표현 가능한 것을 확인 할 수 있다.
'apache-spark(big data)' 카테고리의 다른 글
| apache-spark@3.0.1 설치 (1) | 2020.09.16 |
|---|---|
| apache-spark의 Dataframe(1) - pyspark (0) | 2020.04.29 |
| apache-spark 에서 word count하기(1) - pyspark (0) | 2020.04.27 |
| apache-spark에서 map,lambda 함수 활용하기(2) - pyspark (0) | 2020.04.24 |
| apache-spark에서 map,lambda 함수 활용하기(1) - pyspark (0) | 2020.04.22 |



