
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Histogram
- solidity
- Apache Spark
- MAP
- lambda
- Ethereum
- bigdata
- HelloWorld
- RDD
- word count
- macbook
- 블록체인
- docker
- web3@1.2.8
- Greeter
- Python
- stopwords
- OpenCV
- 이더리움
- python3
- remix
- geth
- node
- BlockChain
- pyspark
- apache-spark
- web3
- Spark
- jenv
- nodejs
- Today
- Total
이것저것 프로그래밍 정리(Macbook)
apache-spark 에서 word count하기(1) - pyspark 본문
대문자, 소문자 변환
단어의 객수 count 하기, word count 하기를 앞서서 대문자로 되어있는 단어와 소문자로 되어있는 단어는 모두 같기 때문에 대소문자 변경하는 것을 먼저 알아보도록 하자.
먼저 예시 dataset을 만들어 보도록 하자.
%%writefile data/ds_bigdata_wcex.txt
big data
big DaTa
BiG data
BIg DAta
aPAche spArk
aPache SpaRk
ApaChe spArk
ApaCHE Spark
위의 데이터를 사용하도록 하겠다.
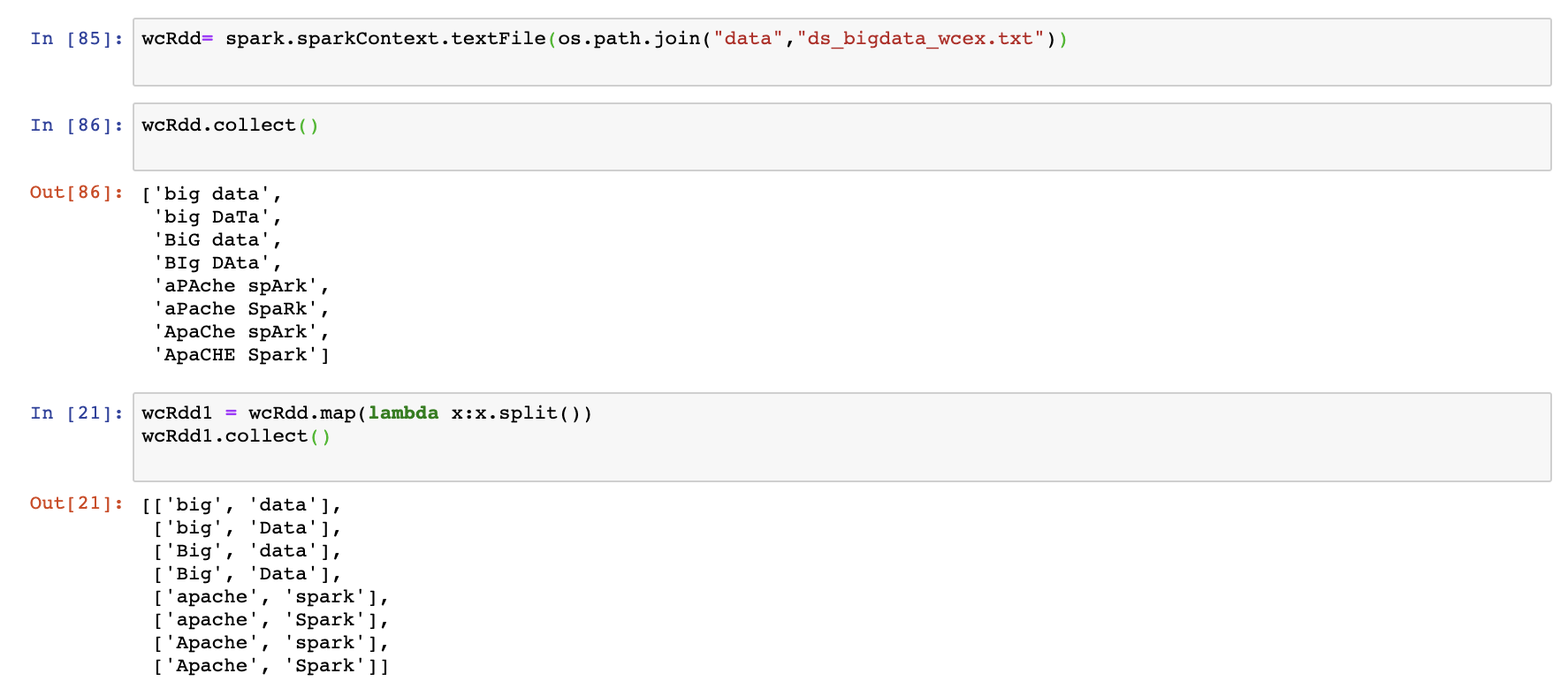
항상 하던 것처럼 RDD를 생성해주고 단어를 분리 시켜주도록 하자.
이후 대문자로 만들어 주는 함수와 소문자로 만들어주는 함수를 만들어 주도록 하자.


만든 함수를 적용해서 각각 대문자와 소문자로 만들어 보도록 하자.

위에서 함수를 만들어서 대문자, 소문자로 변경해 보았다. 이번에는 함수를 사용하지 않고 lambda를 통해 대문자, 소문자로 변환시켜보도록 하자.
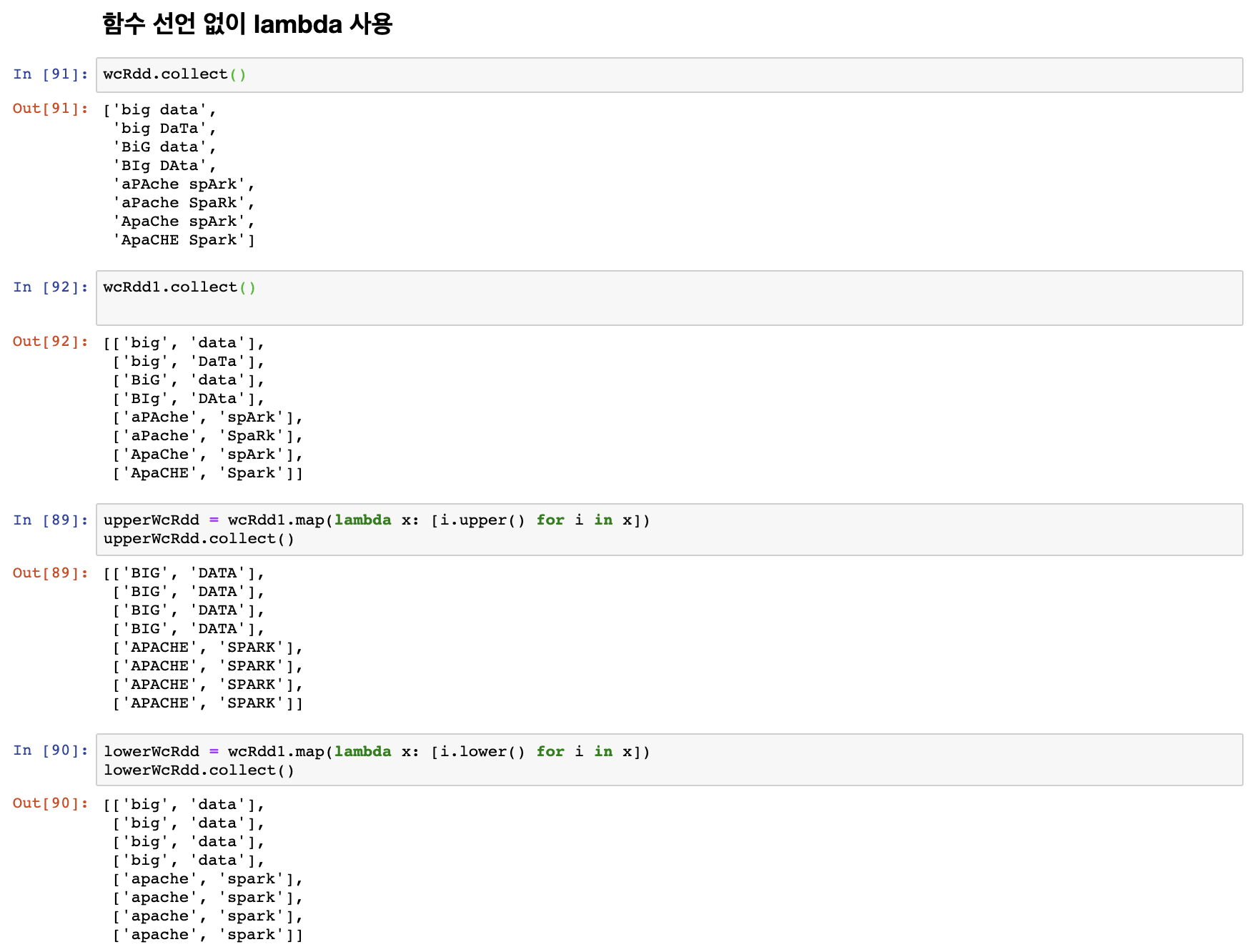
함수 대신 이렇게 lambda를 사용해서 간단하게도 가능하다.
단어 수 count 하기
위의 ds_bigdata_wcex.txt 파일에서 big, data, apache, spark 는 각기 모두 다른 대문자,소문자 구성으로 이루어져 있지만 모두 같은 단어이다. 단어를 모두 소문자로 만든 이후 각 단어가 몇번씩 나왔는지 확인해보도록 하자.

먼저 RDD를 생성 한 이후, 그 RDD를 각 단어를 분리 시켜서 lowerWC라는 RDD를 생성해줬습니다.

이후 모두 소문자로 만든이후 flatMap을 통해 하나의 리스트 안에 넣어줬습니다.

그러고 나서 각 단어를 key,value 값으로 구성된 pair RDD를 생성해 줍니다. pair RDD에 관해서는 다른 글에서 보다 자세히 다루도록 하겠습니다.

pair RDD 생성 이후에 각 값들을 key로 묶은 이후 각 단어가 몇번 등장 하였는지 .mapValues를 통해 확인해줬습니다.
위의 과정은 설명을 위해 여러줄로 코드를 나눈 것이고 이것 들을 한 줄로 만들어 보겠습니다.

이렇게 한줄로 정리 가능합니다.
이렇게 이번 글에서는 대소문자 변경 방법과 word count 하는 법을 알아봤습니다.
다음 글에서는 이제 필요없는 불용어(stopword)를 제거하며 word count 하는 법을 알아보도록 하겠습니다.
'apache-spark(big data)' 카테고리의 다른 글
| apache-spark의 Dataframe(1) - pyspark (0) | 2020.04.29 |
|---|---|
| apache-spark 에서 word count하기(2) - pyspark (0) | 2020.04.28 |
| apache-spark에서 map,lambda 함수 활용하기(2) - pyspark (0) | 2020.04.24 |
| apache-spark에서 map,lambda 함수 활용하기(1) - pyspark (0) | 2020.04.22 |
| apache-spark의 RDD - pyspark (0) | 2020.03.12 |



