
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Ethereum
- macbook
- jenv
- word count
- RDD
- Apache Spark
- remix
- BlockChain
- geth
- docker
- OpenCV
- lambda
- HelloWorld
- node
- apache-spark
- web3
- nodejs
- MAP
- python3
- Greeter
- Python
- Spark
- Histogram
- web3@1.2.8
- 이더리움
- solidity
- stopwords
- bigdata
- 블록체인
- pyspark
- Today
- Total
이것저것 프로그래밍 정리(Macbook)
apache-spark의 Dataframe(1) - pyspark 본문
Dataframe 개요
spark 에서 제공하는 데이터 구조 중 하나이 Dataframe에 대해 알아보도록 하자.
spark에서 많이 사용하는 다른 데이터 구조인 RDD는 schema를 정하지 않는 것과 달리 Dataframe은 모델 schema를 설정해서 사용한다.
Column은 Dataframe의 열에 해당하고, data type을 갖는다. Row는 Dataframe의 행으로, 데이터 요소항목을 묶어서 구성한다. Python에서 list 혹은 dictionary를 사용해서 row를 구성할 수 있다.
Data type으로는 다음과 같은 항목들이 있다.
NullType, StringType, BinaryType, BooleanType, DataType,TimestampType, DoublType, DecimalType, ShortType, ArrayType, MapType이러한 data type들이 존재한다.
RDD와 마찬가지로 Dataframe 역시 머신러닝의 입력데이터로 사용 가능하다.
Dataframe의 주요 API를 살펴보도록 하자.
| 기능 | 설명 | 예제 |
| json | json 읽기 | spark.read.json("ex.json") |
| show | 데이터 읽기 | df.show() |
| schema | data schema 보기 | df.printSchema() |
| select | 열을 선택 | df.select("name") |
| filter | 조건 선택 | df.filter(dfs("age") > 23).show() |
| groupBy | 그룹 | df.groupBy("age").count().show() |
| dropna | na를 삭제 | df.dropna(), df.na.drop() |
| fillna | na를 값으로 채우기 | fillna() |
| count | 행 count | df.count() |
| drop | 삭제 | df.drop("name") |
Dataframe 생성하기
dataframe 생성 방법으로 크게 외부에서 읽어오는 것과, 내부에서 읽어오는 것 두가지로 나누어 볼 수 있다.
| 생성 방법 | 설명 | 함수 |
| 외부에서 읽기 | Hive, csv, JSON, RDB, XML, RDD 등 | spark.createDataFrame() 또는 spark.read() |
| 내부에서 읽기 | python list,dict 또는 pyspark.sql.Row 객체를 사용하여 한줄씩 생성 가능 | spark.createDataFrame() |
spark.createDataFrame() 함수는 RDD 또는 list와 같은 데이터에서 dataframe을 생성한다.
반면 spark.read() 함수는 csv, json 과 같은 파일에서 데이터를 읽을 수 있다.
schema 자동 인식해서 dataframe 생성하기
python 자료구조를 사용해서 dataframe을 생성해 보자.
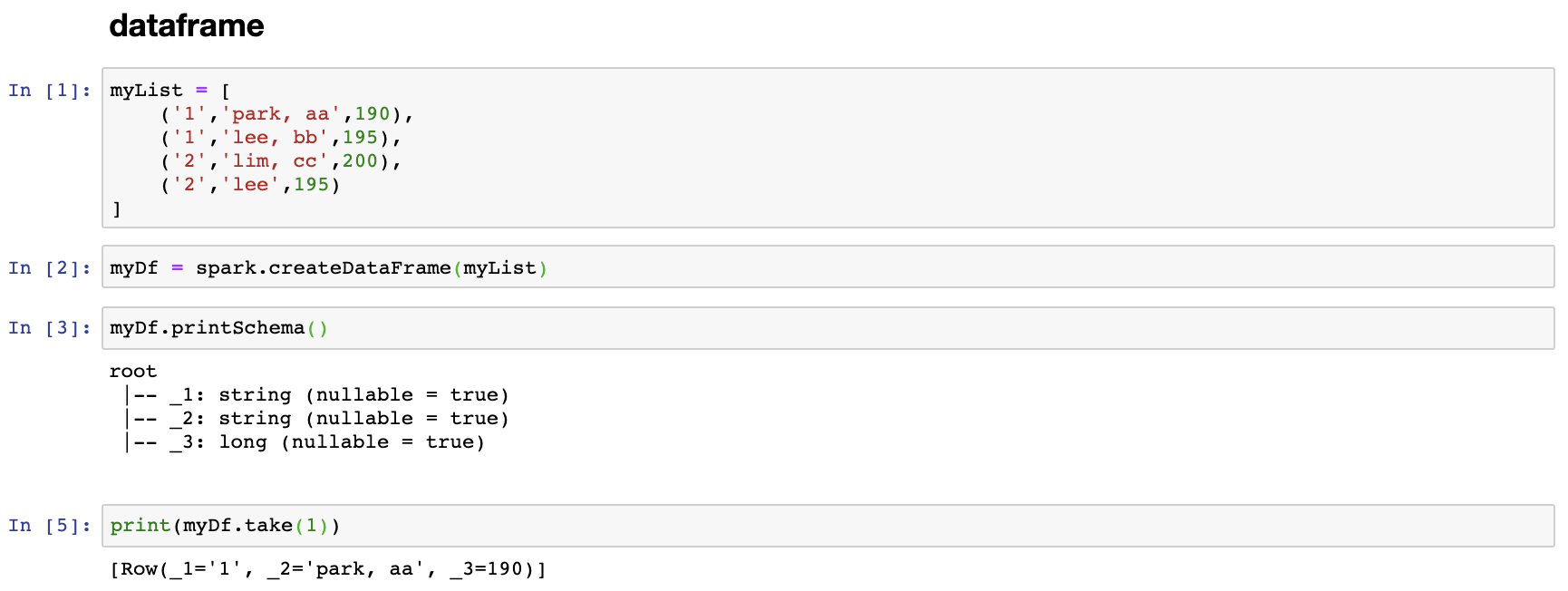
위처럼 dataframe을 생성시 spark가 자동으로 schma를 설정한다.
생성한 dataframe을 printSchema() 를 통해 schema를 출력해 보도록 하자.
컬럼명은 일련번호로 _1, _2,_3 과 같이 생성된다.
data type도 알아서 유추해서 생성되나, 올바르게 않게 생성될 수 있으니 이 점을 유의해 두도록 하자.
컬럼명을 설정하지 않고 프린트 해줬기 때문에 컬럼명이 _1,_2 이런식으로 생성되었는데 이번에는 컬럼명을 우리가 원하는데로 설정해 보도록 하자.
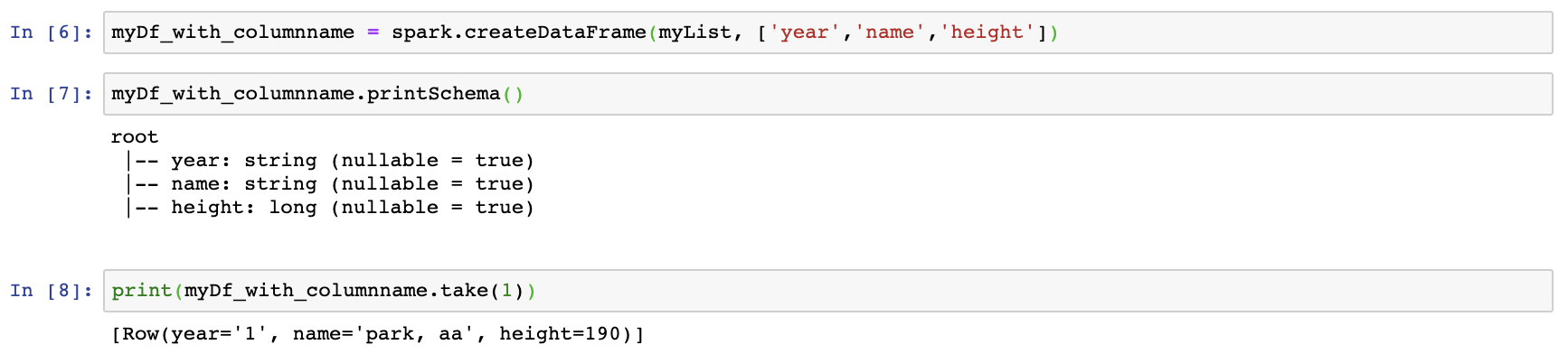
다음과 같이 dataframe을 생성할때 컬럼명을 함께 설정해 줄 수 있다.
이후 , .show()를 통해 dataframe 전체를 확인해 보도록 하자.

Row 객체를 사용해서 dataframe 생성하기
이번에는 row 를 사용해서 dataframe을 생성해 보도록 하자.

마찬가지로 생성한 dataframe을 .show()를 통해 확인해보자.

schema 정의하고 dataframe 생성하기
이번에는 data type을 정의 한 이후에 dataframe을 생성해보도록 하자.
예시를 통해 보는 것이 빠르니 예시를 통해 생성해보자.
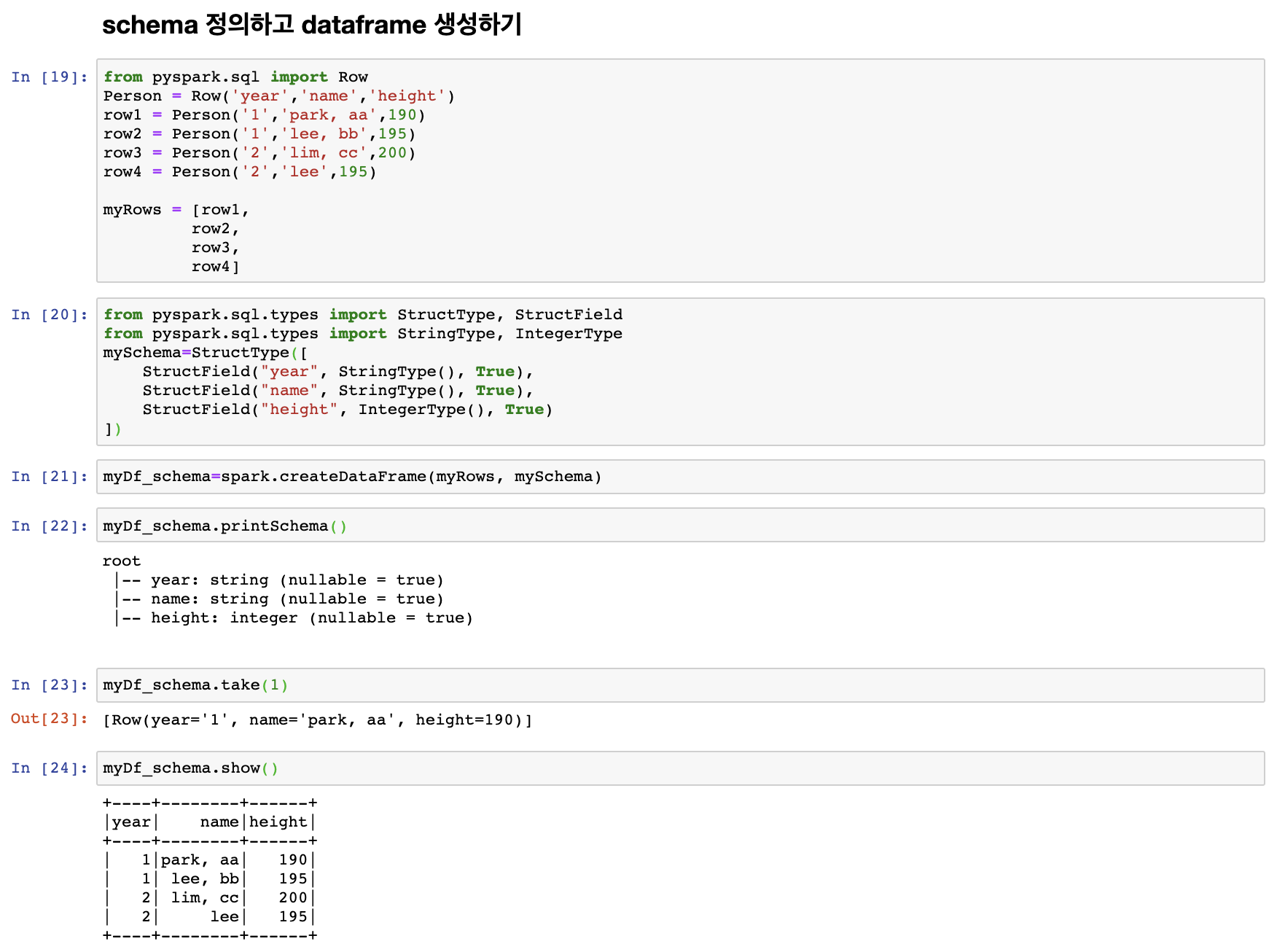
위에서 mySchema 처럼 data type을 설정한 이후에 schema를 생성 할 수도 있다.
이후 생성해 놓은 myRows 와 mySchema를 이용해서 dataframe을 생성한 것을 확인 할 수 있다.
RDD에서 생성하기
RDD는 schema가 정해지 않은 비구조적 데이터이다. 따라서 schema를 따로 정의하지 않으면 schema를 유추해서 dataframe을 생성한다.
RDD에서 schema 자동 인식, schema 정의하고 dataframe 생성하는 2가지 방법을 보도록 하자.
Schema 자동 인식
toDF()로 변환하거나 createDataFrame()를 사용하여 dataframe을 생성할 수 있다.
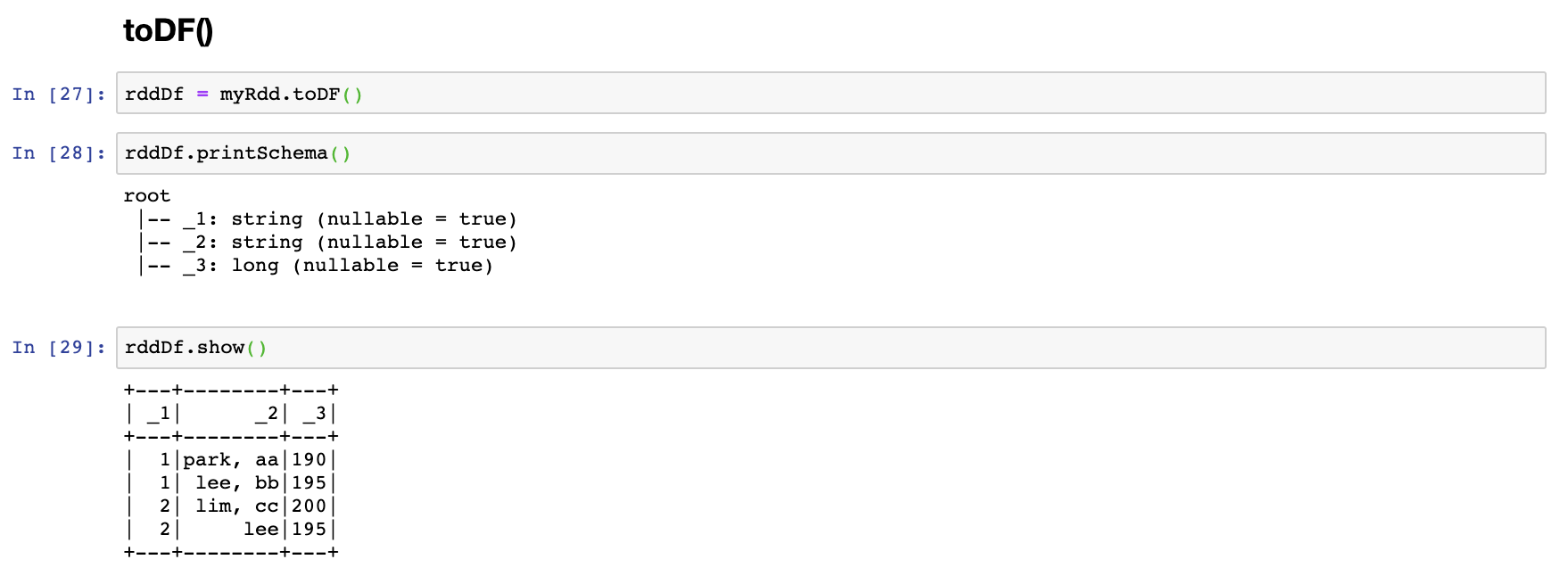
먼저 toDF() 방법을 알아보도록 하자.
toDF()
먼저 list에서 RDD를 생성해 주도록 하자.
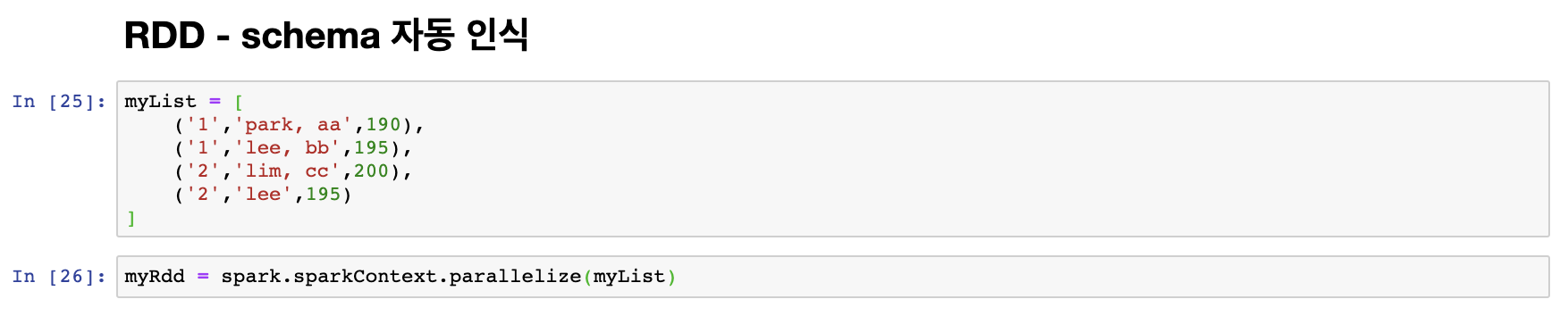
이후 생성된 RDD를 toDF()를 통해 dataframe으로 변화해 주도록 하자.
createDataFrame()
같은 방식으로 이번에는 createDataFrame() 방법을 알아보도록 하자.

dataframe은 DBMS의 테이블과 매우 유사하다. sql과 비슷하기 where(),select(),groupby() 함수가 사용 가능하다.

where, select를 이용해서 컬럼 _3 이 195이상인 행들의 컬럼 _1, _2 값들을 show() 해줬다
이번에는 groupby를 이용해 보도록 하자.

이번에는 컬럼 _1 값으로 groupby 한 이후 같은 최대값 max()를 구해 본 것이다.
groupby하면 행의 값으로 구분 지어서 평균, 갯수, 최대, 최소, 등을 구할 수 있다.
Schema 정의하고 dataframe 생성하기
이번에는 Schema를 정의하고 dataframe을 생성해 보도록 하자.
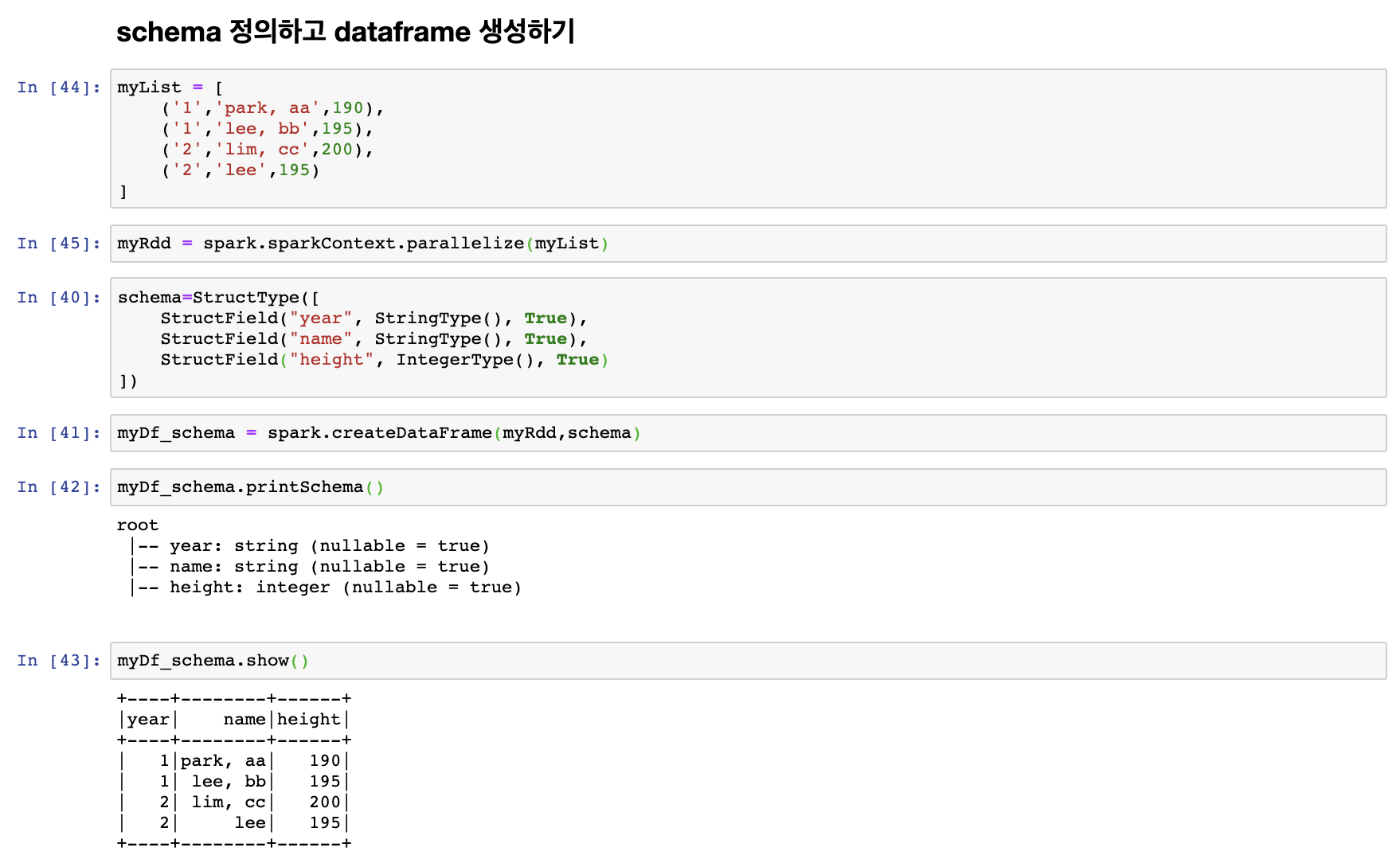
다음과 같이 RDD를 생성하고 schema를 정의한 후 dataframe 생성하는 것도 가능한 것을 확인 할 수 있다.
다음 글에서부터는 csv 파일에서 dataframe을 생성하는 방법과 schema 설정하는 방법을 알아보도록 하자.
'apache-spark(big data)' 카테고리의 다른 글
| pip에서 pyspark 라이브러리 설치해서 이용하기 (2) | 2020.12.10 |
|---|---|
| apache-spark@3.0.1 설치 (1) | 2020.09.16 |
| apache-spark 에서 word count하기(2) - pyspark (0) | 2020.04.28 |
| apache-spark 에서 word count하기(1) - pyspark (0) | 2020.04.27 |
| apache-spark에서 map,lambda 함수 활용하기(2) - pyspark (0) | 2020.04.24 |



