
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- BlockChain
- word count
- macbook
- jenv
- Greeter
- lambda
- Python
- RDD
- 블록체인
- OpenCV
- pyspark
- 이더리움
- nodejs
- apache-spark
- web3
- docker
- MAP
- python3
- remix
- bigdata
- solidity
- Ethereum
- stopwords
- node
- geth
- Spark
- web3@1.2.8
- Histogram
- Apache Spark
- HelloWorld
Archives
- Today
- Total
이것저것 프로그래밍 정리(Macbook)
pip에서 pyspark 라이브러리 설치해서 이용하기 본문
반응형
apache spark를 설치하지 않고 pip를 통해서 pyspark를 설치해서 jupyter notebook 또는 python shell에서 사용도 가능합니다.
한 번 알아보도록 하겠습니다.
1. pip 이용해서 pyspark 설치하기
먼저 터미널에서 pip를 이용해서 pyspark를 설치해 주도록 하겠습니다.
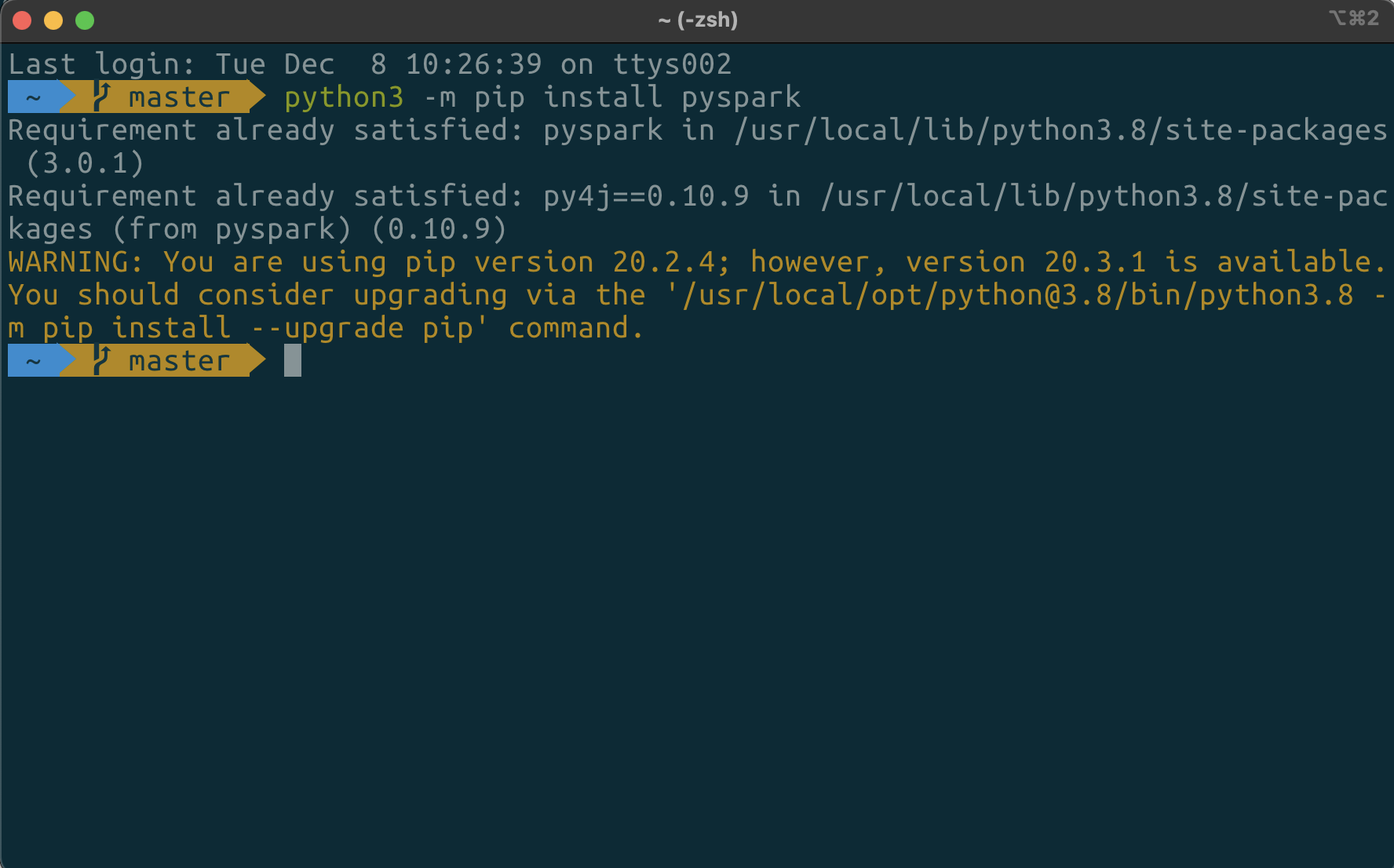
python3 -m pip install pyspark
위 명령어를 통해서 pyspark 라이브러리를 설치 해줬습니다.
2. SparkSession 생성하기
spark를 사용하기 위해서 SparkSession 객체를 생성하고 사용하면 된다.
먼저 사용한 pyspark 라이브러리를 import 해주도록 하겠습니다.
여기서부터는 jupyter notebook 환경에서 진행하면 됩니다.

import pyspark
이후 SparkSession을 생성해주도록 하겠습니다.

myConf = pyspark.SparkConf()
spark = pyspark.sql.SparkSession.builder.getOrCreate()
위 명령어를 통해 SparkSession을 생성해면 이제 spark 를 사용할수 있습니다.
실제로 간단히 사용해보도록 하겠습니다.
3. spark 사용해보기
간단한 RDD를 생성하고 이후 DataFrame도 생성해보도록 하겠습니다.
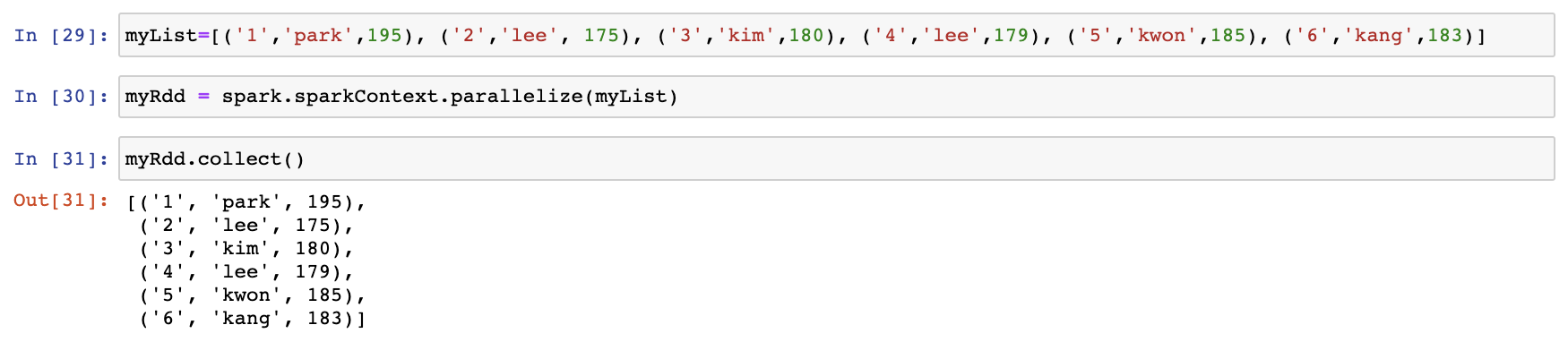
간단한 list를 생성한 이후 이를 RDD로 변환해 보았습니다.
위 예제와 같이 pyspark 라이브러리를 이용해서 spark를 사용할 수 있습니다.
이번에는 위 RDD를 DataFrame으로 변환해 보도록 하겠습니다.
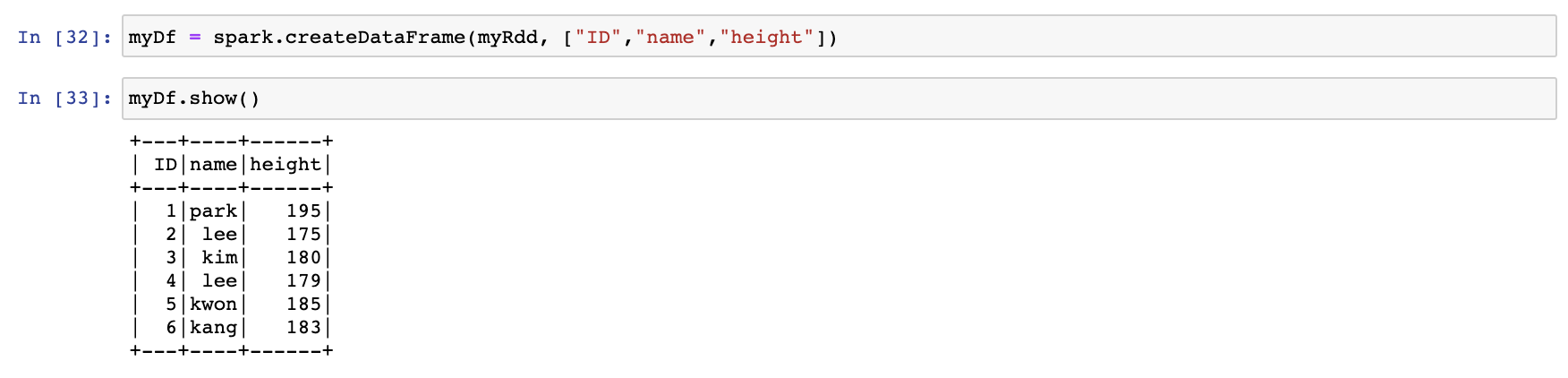
위와 같이 spark의 기능들을 모두 쓸수 있습니다.
이상입니다!!
반응형
'apache-spark(big data)' 카테고리의 다른 글
| apache-spark ML을 이용한 Logistic Regression - pyspark (0) | 2020.12.22 |
|---|---|
| apache-spark@3.0.1 설치 (1) | 2020.09.16 |
| apache-spark의 Dataframe(1) - pyspark (0) | 2020.04.29 |
| apache-spark 에서 word count하기(2) - pyspark (0) | 2020.04.28 |
| apache-spark 에서 word count하기(1) - pyspark (0) | 2020.04.27 |
'apache-spark(big data)' Related Articles
more




Comments