
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- node
- Python
- 이더리움
- solidity
- docker
- BlockChain
- HelloWorld
- Apache Spark
- MAP
- bigdata
- RDD
- Ethereum
- word count
- jenv
- lambda
- python3
- Histogram
- 블록체인
- Spark
- pyspark
- OpenCV
- web3
- apache-spark
- macbook
- remix
- stopwords
- Greeter
- web3@1.2.8
- nodejs
- geth
- Today
- Total
이것저것 프로그래밍 정리(Macbook)
apache-spark ML을 이용한 Logistic Regression - pyspark 본문
apache-spark ML을 이용한 Logistic Regression - pyspark
parkaparka 2020. 12. 22. 16:09Logistic Regression(로지스틱 회귀)은 발생할 결과 값이 이진인 경우의 분류에 적용합니다.
예를 들어 환자의 데이터로부터 병의 유무, 이메일이 스팸인지 아닌지 등 이진 분류일 때 적용 가능합니다.
예제를 통해 pyspark에서 Logistic Regression의 사용법을 알아보도록 하겠습니다
건강 지표들을 통해 심장병의 유무에 대해 예측해보고 얼마나 정확한지 측정해 보도록 하겠습니다.
0. 필요 라이브러리 import하기
필요한 라이브러리들을 먼저 import 해놓도록 하겠습니다.

1. 데이터 불러오기
다음 아래의 csv 파일을 DataFrame으로 불러오도록 하겠습니다.

위 사진과 같이 trainDf를 생성해 주었습니다.
trainDf의 column들은 다음과 같습니다.

현재 trainDf의 schema는 다음과 같습니다.

target을 double형으로 변환 해 주고, 건강 지표와 상관 없는 cp, thal, slope column을 drop 해 주도록 하겠습니다.
그리고 나서 변경된 schema를 확인해 보도록 하겠습니다.


이후 dataframe df를 test 데이터와 train 데이터로 7:3 비율로 나누어 주도록 하겠습니다.

이후 train은 train data인 것을 알려주기 위해 새로운 column을 생성해서 train이라고 입력하고 test는 test data인 것을 알려주기 위해 새로운 column을 생성하고 test라고 입력해 주도록 하겠습니다.

그리고 두 데이터를 다시 하나의 dataframe으로 합친 이후 각각 train, test가 몇개씩 있는지 확인해 보도록 하겠습니다.

2. Feature vector 구성하기
target1, testOrtrain column을 제외하고 나머지 column들을 VectorAssembler를 통해 Feature Vector를 생성해 주도록 하겠습니다.

이후 과정이 한 단계이기는 하지만, 다른 예제의 경우에는 여러단계가 있을 수 있기에 파이프라인으로 구성해 주겠습니다.

그러고 나서 fit()을 통해 모델을 생성해 주도록 하겠습니다.

만든 모델에 생성되어 있는 DataFrame인 df를 넣어서 feature column이 생성되어 있는 myDf를 생성해 주도록 하겠습니다.
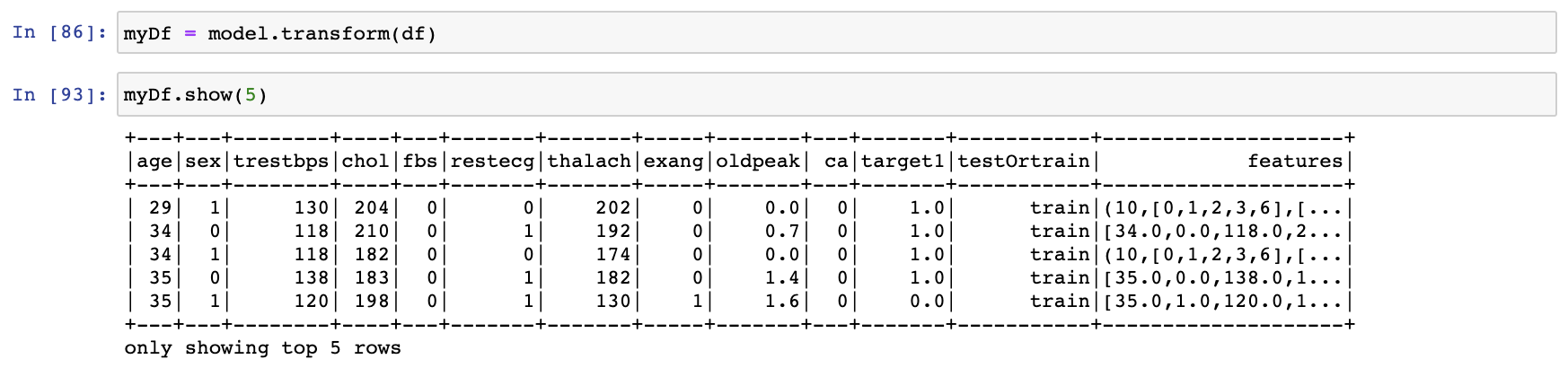
3. Train, Test 데이터
testOrtrain column에 train으로 되어 있는 것을 분리 시킨 이후 7:3 비율로 train 데이터와 validate 데이터로 나눠주겠습니다.

testOrtrain column에 test로 되어 있는 것을 분리시켜주도록 하겠습니다.

4. LogisticRegression 모델링
이제 logisticRegression 모델을 생성해 주도록 하겠습니다.

이제 생성된 모델에 trainDf를 fit() 해 주도록 하겠습니다.

5. 예측
생성하고 학습시킨 모델에 평가 데이터인 validateDf를 transform()해서 심장병이 걸릴지 안걸리지 예측 값인 prediction column을 확인해 보겠습니다.

validateDf의 실제 심장병 유무인 target1과 prediction을 출력해서 확인해 보겠습니다.

6. 평가
evaluatorBinaryClassificationEvaluator를 이용해서 얼마나 정확한 확률로 예측했는지 확인해 보도록 하겠습니다.

다음과 같이 77%의 확률로 예측에 성공한것을 확인 할 수 있습니다.
'apache-spark(big data)' 카테고리의 다른 글
| pip에서 pyspark 라이브러리 설치해서 이용하기 (2) | 2020.12.10 |
|---|---|
| apache-spark@3.0.1 설치 (1) | 2020.09.16 |
| apache-spark의 Dataframe(1) - pyspark (0) | 2020.04.29 |
| apache-spark 에서 word count하기(2) - pyspark (0) | 2020.04.28 |
| apache-spark 에서 word count하기(1) - pyspark (0) | 2020.04.27 |



